from Dictionary - Caching
프로젝트에서 Redis로 캐싱 전 찾아본
캐싱 전략
캐싱 전략은 웹 서비스에서 시스템 향상을 기대할 수 있는 중요 기술이다.
기본 지식
- cache hit : 캐시 스토어에 데이터가 있는 경우
- cache miss : 캐시 스토어에 데이터가 없을 경우
주요 고려 사항
캐시를 사용하면 데이터 정합성 문제가 발생한다. 따라서 적절한 캐시 읽기 전략(Read Cache Strategy)과 캐시 쓰기 전략(Write Cache Strategy)으로 데이터 불일치 문제를 극복하면서 성능 또한 잡아야 한다.
캐시 읽기 전략( Read Cache Strategy )
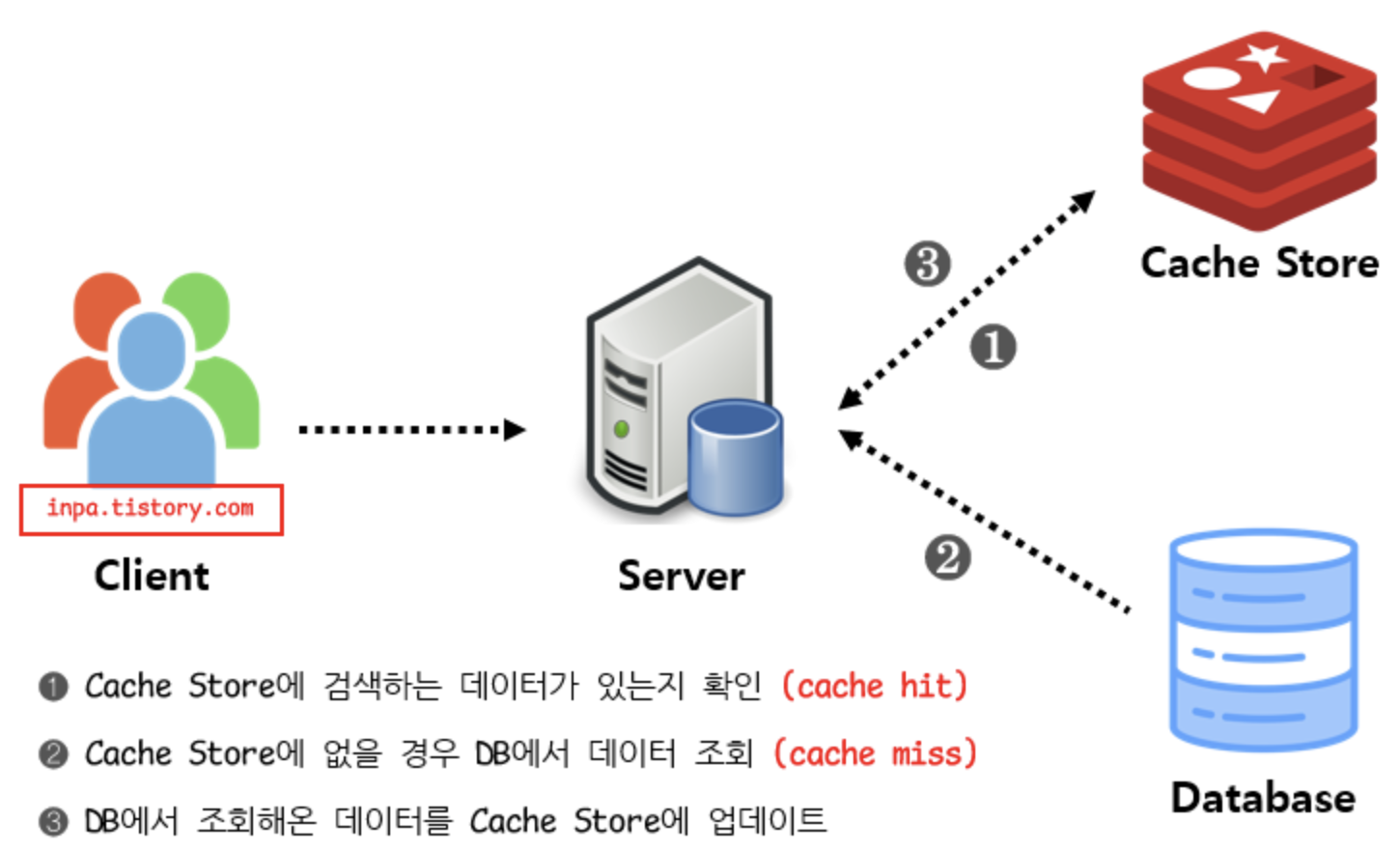
1. Look Aside
특징
- Cache Aside 패턴
- 데이터를 찾을 때 우선 캐시에 저장된 데이터가 있는지 우선적으로 확인 없으면 DB에서 조회
- 반복적 읽기가 많은 호출에 적합
- 캐시, DB가 분리되어 가용. 원하는 데이터만 별도로 구성하여 캐시에 저장
- 캐시, DB가 분리되어 있어 캐시 장애에 대응 가능
- Cache Store, Data Store 간의 정합성 유지 문지가 발생할 수 있다.
- 초기 조회시 DB를 무조건 조회해야 하므로 단건 호출 빈도가 높은 서비스에서는 적합하지 않다. 대신 반복적으로 동일 쿼리를 호출하는 경우 좋다.
[Cache Warming] 미리 Cache로 DB 데이터를 밀어 넣는 작업. 이 작업을 하지 않으면 초기 트래픽 증가 시 cache miss가 발생해서 부하가 급장할 수 있다. expire되면 Thundering Herd가 발생할 수 있으므로 TTL 조정이 필요하다.
[Thundering Herd] 캐시 데이터가 휘발됐을 때 다수의 프로세스가 하나의 이벤트를 기다리며 Waiting에 있다 해당 이벤트가 발생했을 때 모든 프로세스들이 동시에 wake-up하며 자원을 낭비할 때 발생
-> 동일한 많은 요청이 들어왔을 때 하나의 Cache miss만 원본 서버에 요청하고 나머지 요청은 잠시 대기 시킨 후, 응답이 오면 그 응답을 반환하게 하는 방법으로 해결 가능
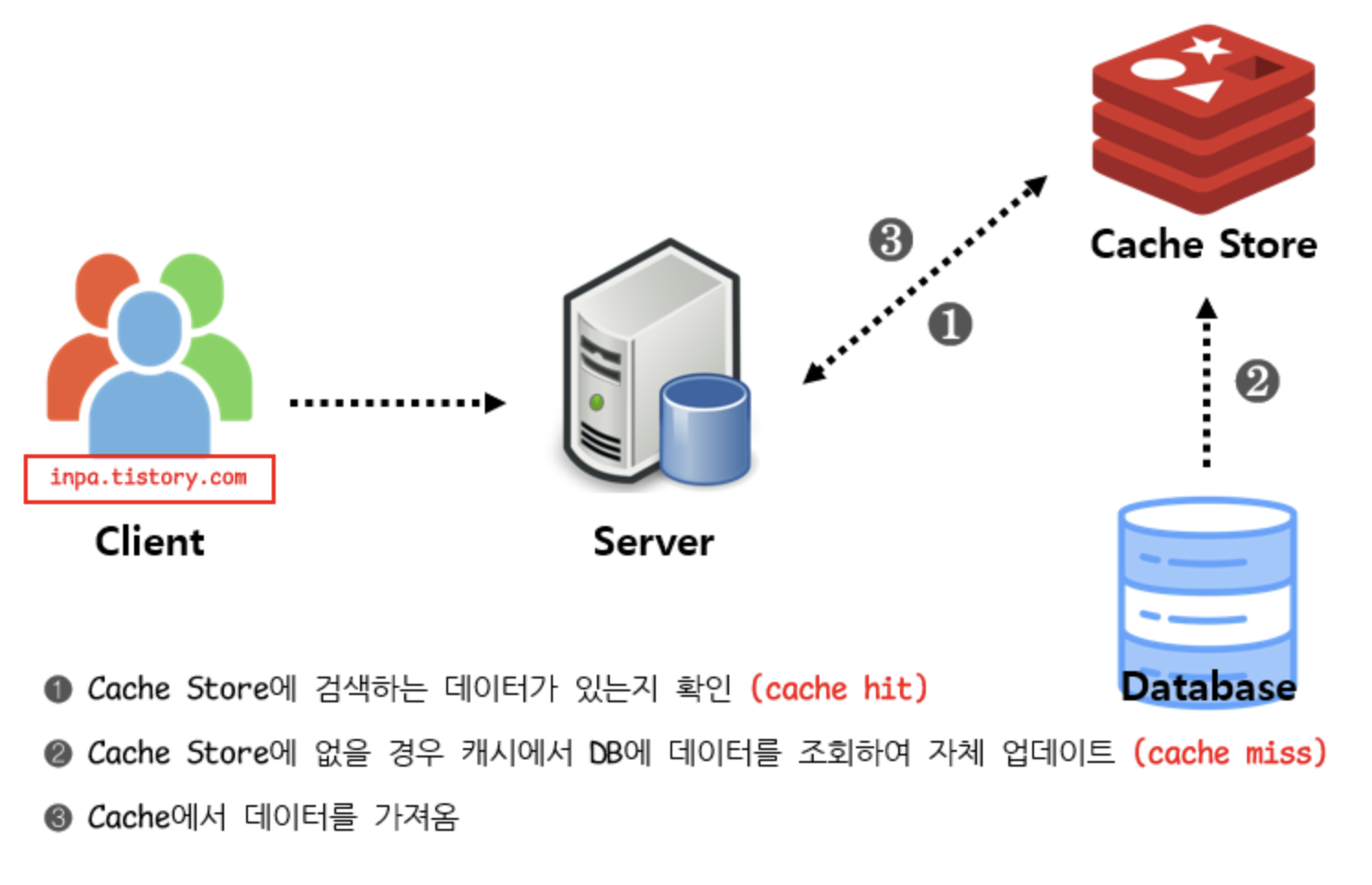
2. Read through 패턴
특징
- 캐시에서만 데이터를 읽어오는 전략 (inline cache)
- Look Aside와 비슷하지만 데이터 동기화를 라이브러리 또는 캐시 제공자에게 위임하는 방식
- 데이터 조회 속도가 전체적으로 느림
- 데이터 조회를 전적으로 캐시에만 의지하므로 캐시 서버가 다운되면 서비스 이용에 문제가 생길 수 있음
- 위 문제는 Redis를 replication 또는 Cluster 구성으로 극복할 수 있다.
- 캐시, DB 간 데이터 동기화가 항상 이뤄져서 정합성 문제에서 자유로움
- 읽기가 많은 워크로드에 적합
- Cache Aside와 비슷하지만 CacheStore 저장 주체가 Server냐, DataStore이냐 차이
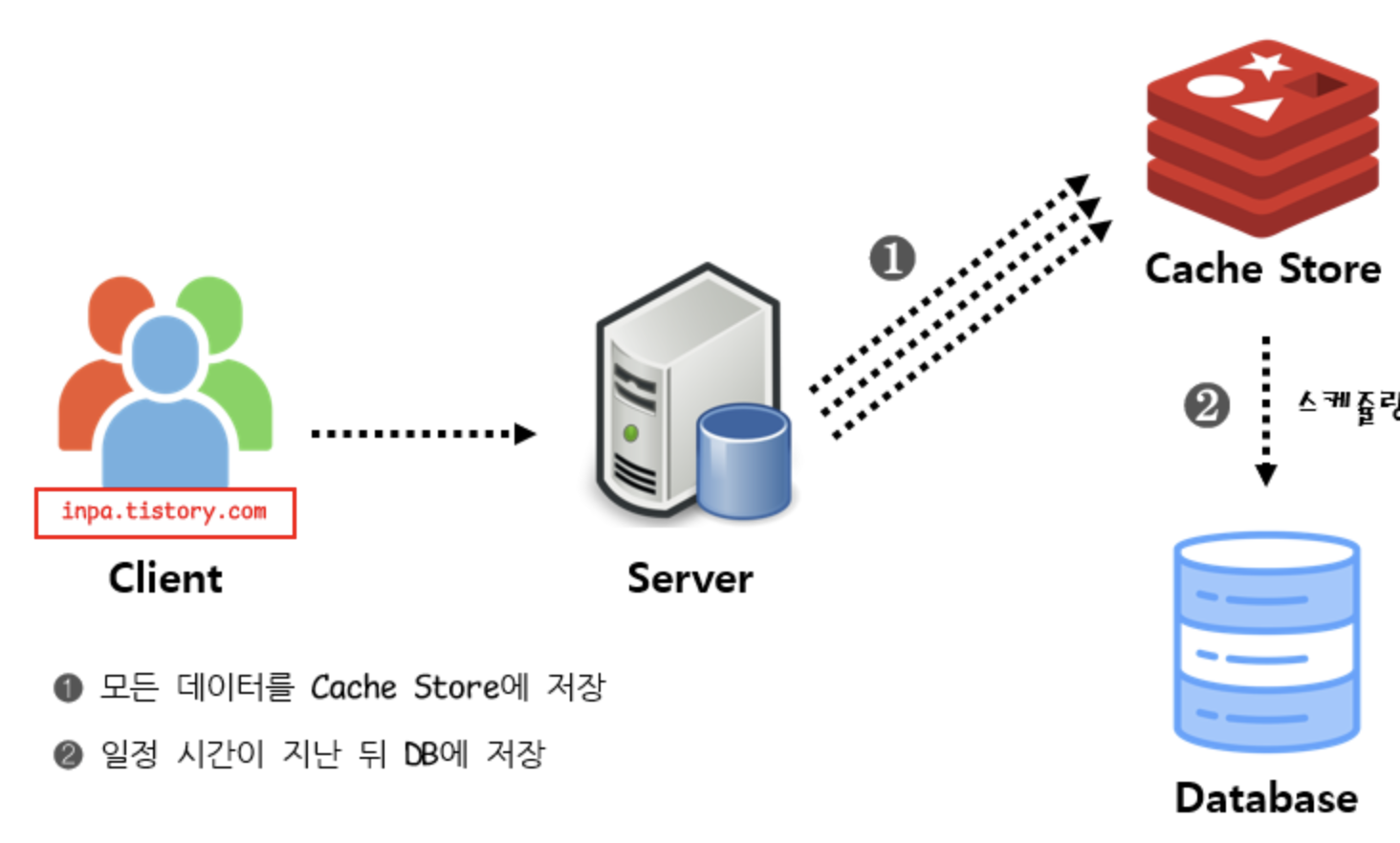
캐시 쓰기 전략 (Write Cache Strategy)
1, Write Back
특정
- Write Behind 패턴이라고도 불린다.
- 캐시오 DB 동기화를 비동기하기 떄문에 동기화 전략이 생략
- 데이터를 저장할 떄 DB에 바로 쿼리하지 않고 캐시에 모아서 일정 주기 배치 작업을 통해서 진행
- 캐시에 모아놨다 한 번에 쓰므로 쓰기 쿼리 비용을 줄일 수 있음
- Write가 빈번하면서 Read하는데 많은 양의 Resource가 소모되는 서비스에 적합
- 데이터 정합성 확보
- 자주 사용되지 않은 불필요한 리소스 저장
- 캐시에서 오류가 생기면 데이터를 영구 소실
- Write back 방식은 DB가 아니라 캐시에 먼저 저장하여 Queue로 사용하고, 특정 시점마다 DB로 flush 하는 방식이다.
- DB에 장애가 생겨도 캐시가 살아있으면 서비스를 계속할 수 있음
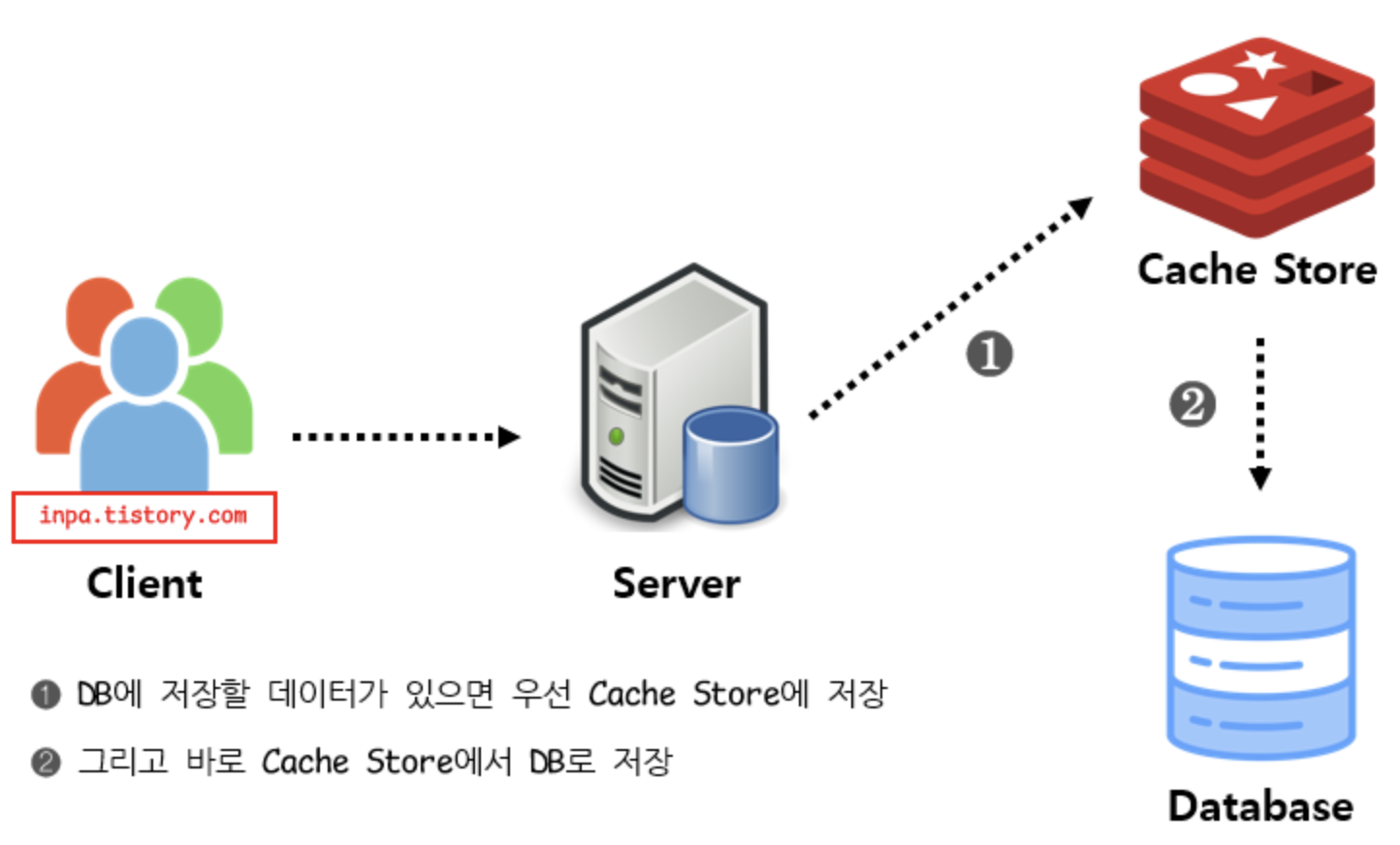
2. Write Through 패턴
특징
- DB와 Cache에 동시에 데이터를 저장
- 데이터를 저장할 때 캐시에 먼저 저장하고 DB로 바로 저장
- Read Through와 마찬가지로 DB 동기화를 캐시에 위임
- DB와 캐시가 항상 동기화 되어 있어, 캐시 상테는 항상 최신
- 캐시와 백업 저장소 업데이트를 같이 해서 데이터 일관성을 유지할 수 있으서 안정적이다.
- 데이터 유실이 발생하면 안되는 곳에 사용
- 자주 사용하지 않는 불필요한 리소스를 저장할 수 있음
- 빈번한 Write가 생길 수 있음
- 기억 장치 속도가 느리면 CPU 유휴 시간 증가
- 캐시에 넣은 데이터를 저장만 하고 사용하지 않을 수도 있다.
WriteThrough, WriteBack 모두 쓰지 않은 데이터를 저장하며, 리소스 낭비를 줄이기 위해서 TTL을 설정해야 한다.
3. Write Around
특징
- Write Through보다 빠름
- 모든 데이터는 DB에 저장
- Cache miss가 발생하면 DB와 캐시에도 데이터를 저장
- DB, Cache 간 데이터 정합성에 문제가 있을 수 있
캐시 읽기 + 쓰기 조합
1. Look Aside + Write Around
Read는 (Cache || DB) -> ( hit - cache / miss - DB ) + Write는 DB로
2. Read Through + Write Around
Read는 Cache (hit -> cache / miss -> 캐시가 DB에서 당겨옴 ) + Write는 DB에
(항상 DB에 쓰고 읽을 때 DB에서 읽어오므로)
3. Read Through + Write Through
Read는 Cache (hit -> cache / miss -> 캐시가 DB에서 당겨옴 ) + Write(Cache -> DB)
저장 방식 지침
- 자주 사용되면서 자주 변경되지 않는 데이터를 캐싱한다.
- 캐시는 휘발성을 가져야 한다. ( 어느 정도 데이터 수집과 저장 주기를 가지도록 설계 해야 한다. )
- 데이터 유실, 정합성이 꺠질 수 있으므로 중요한 정보, 민감한 정보는 캐싱하지 않는 방향으로 한다.
파레토의 법칙 ( 8 : 2 법칙 ) 전체 결과의 80%가 전체 원인의 20%에서 일어나는 현상
삭제 방식 지침
- 영구 저장소 복사본으로 동작하므로 데이터 동기화가 필요하다.
- 캐시 구성에 만료 정책을 정해야 한다.
Cache Stampede 현상
대규모 트래픽에서 TTL을 너무 작게 하면 Key Expire 순간, 여러 프로세스가 Key를 조회하면 DB로 Duplicated read를 한다. 또 읽어온 값을 Redis에 Duplciate Write하는 경우도 발생할 수 있다. 따라서 쓸데 없는 작업을 수반하는 현상을 의미한다.
캐시 가용성
캐시 구성하는 목적은 빠른 성능 확보와 데이터 전달에 있다.